1. 모델 성능 평가
테스트 데이터에 대한 성능을 일반화 하는것이 목적
하지만 우리는 학습에 사용하지 않은 unseen데이터는 가지고 있지 않음
즉, 목적은 어떤 데이터든지간에 결과를 일반화하는 거지만 학습과 테스트 모두 가지고 있는 데이터로만 할 수 밖에 없는 상황임

unssen 데이터와 train데이터가 iid라고 가정! => 독립, 같은분포
데이터 분할 방식
교차검증
학습데이터 여러개로 나눠서 fold가 1번씩은 검증데이터가 되도록 => 과적합방지
평가 전략
일정 시간을 두고 학습과 테스트 진행
규제
L1
L2

mse만 최소화하면 오버피팅이 발생하므로 값을 추가하여 규제함, 단 람다가 너무 크면 언더피팅 확률이 올라감
분류에서 accuracy를 측정해서 정확도를 판별하는데 문제점 존재
데이터의 가중치가 다르거나 개수가 다른경우 accuracy 값 의미x

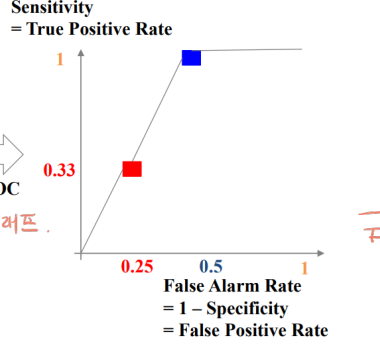
roc curve
x축을 false alarm, y축을 sensitivity로 두고 그린 함수
스레쉬홀드(경계값)에 따라 달라짐
Test methods
realdata가 학습한 데이터 분포인지 어떻게 테스트 할까?
베이스라인 : 랜덤, 제로, 심플 휴리스틱보단 성능이 좋아야한다.
사람과 비교해서 어느 성능?, 기존 문제 해결능력?
(1) perturbation tests
문제 : 유저의 인풋은 노이즈가 있다!
예시 : 음성, 이미지 등...
아이디어 : 노이즈들 첨가해서 아웃풋 바뀌는거 관찰 ㄱㄱ
만약 노이즈를 조금 추가했는데 아웃풋이 심하게 바뀐다? 그러면 우린 모델 강화해야함
해결책 : 노이즈를 테스트할 때 추가, 더 많은 학습 데이터로 학습, 다른 모델 고려
(2) invariance tests
문제 : 아웃풋에 영향을 주면 안되는 인풋이 영향을 줘
예시 : 성별이 점수로 환산 된다거나...
아이디어 : 민감값을 무작위로 조금씩 바꾸면서 변화 살피기
만약 민감값의 변화가 모델의 아웃풋을 바꾸면 편향된 모델임
(3) directional expectation tests
문제 : 인풋이 예측한 아웃풋을 내야하는데 안돼!
예시 : 땅크기랑 가격 비례하지 않아
아이디어 : 값을 바꿔야 하는 특징 몇개만 바꿔서 아웃풋 보기
만약 땅크기에 가격이 비례하지 않으면 조사해야됨 왜 그런지
(4) slice - based evaluation
문제 : 그룹마다 다른 성능
예시 : 서브그룹은 성능이 나빠
문제 : 다른 가중치인 두 그룹이 같은 성능
예시 : 우수고객 지불가격
=> 오직 전체만 보고 성능향상하면 서브그룹에 성능이 저하될 수 있어
simpson's 역설
전체적인 성능은 높지만 그룹별 성능이 안좋다.
그룹을 많이 나누면 좋다.
어떻게 나눠?
전문가한테 맡겨, 에러 분석, 그룹을 찾아
'머신러닝' 카테고리의 다른 글
| 9. Neural Networks (0) | 2023.12.18 |
|---|---|
| 7. Decision Tree (0) | 2023.12.17 |
| 5장 Nearest Neighbor Method (0) | 2023.10.25 |
| 4장 Logistic Legression (0) | 2023.10.25 |
| 3장 Regression (1) | 2023.10.24 |



